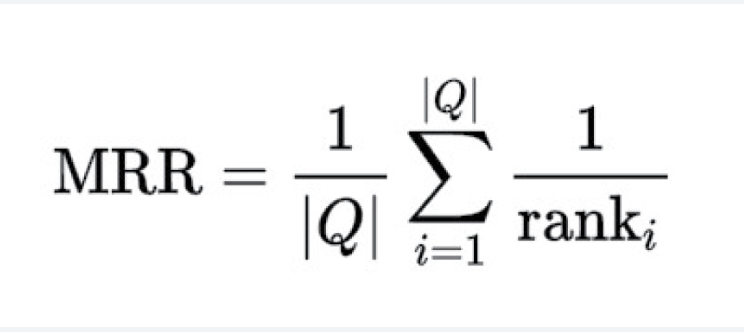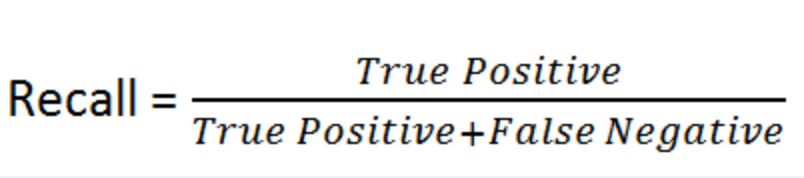Information retrieval is a tool that almost everyone is familiar with. If you have ever used a search engine (Google, Bing, Amazon, Online Store search etc.) then you have used information retrieval. Google’s Search statistics show that there are over 8.5 billion searches over a day. Search engines play a large role in everyone’s day to day life, whether it is for school, work, or need of a quick answer, we are constantly online making search requests. With the increasing demand for computational power, the energy consumption of computers has also increased significantly. Therefore, it is important to find ways to reduce energy consumption while maintaining or increasing computational power. Saving even a small amount of energy can make a significant difference when considering the billions of computations performed daily. Our goal is to improve search engines by decreasing the time in the retrieval process to reduce energy consumption.
Formally, the goal of Information Retrieval is, given a specific text query, retrieve a set of pre-existing text documents (or used interchangeably, passages ) that are most relevant to the given query. There is a long history of research on this problem, with techniques ranging from pure linguistics to utilizing neural networks in recent times. One of the cutting-edge algorithms today is SPLADE, which will be the baseline our project attempts to improve on.
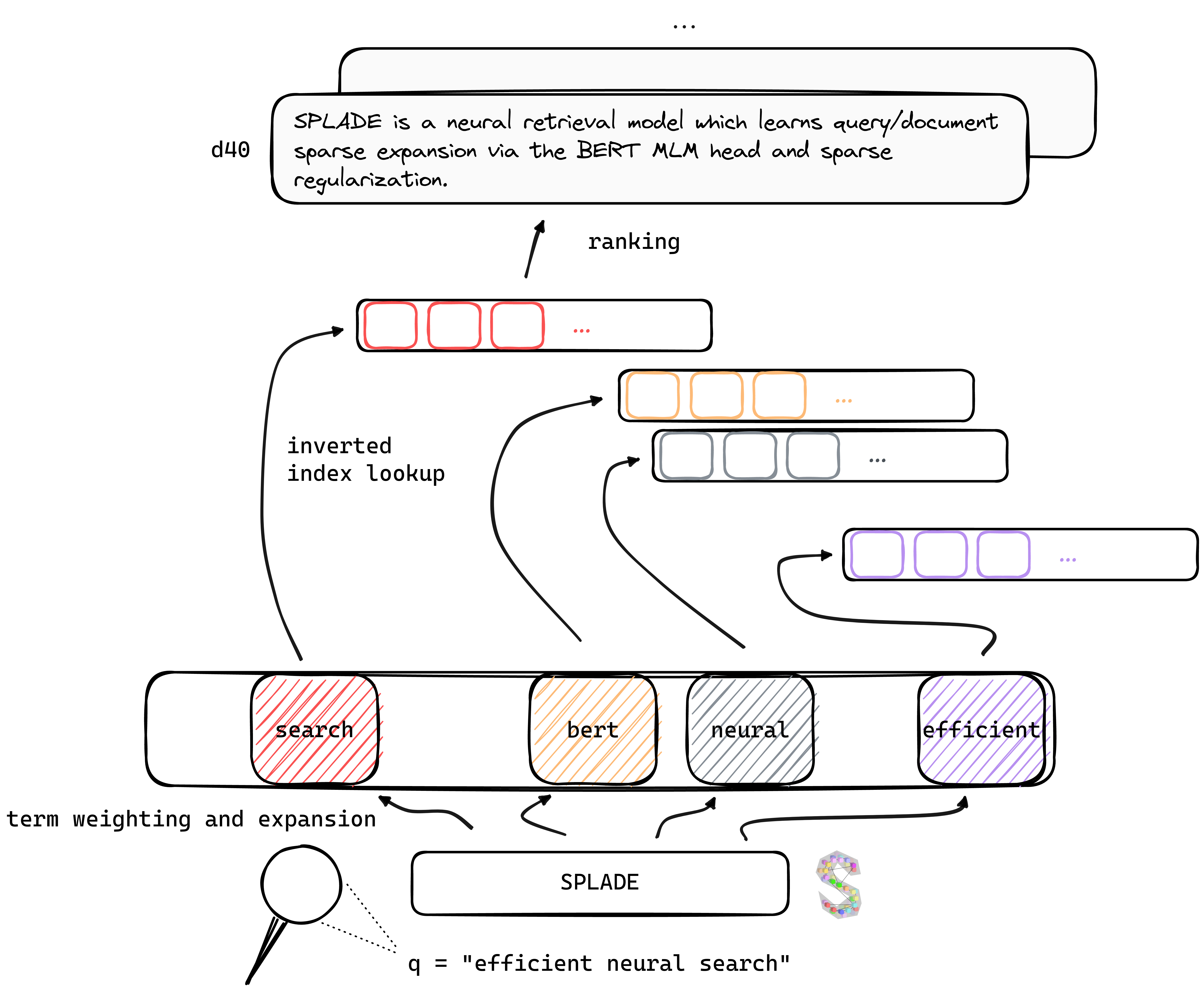
SPLADE stands for Sparse Lexical AnD Expansion Model. It is part of a family of algorithms based on the “Bag
of Words” model of text, but also contains term expansion
capabilities.
At a high level, SPLADE trains a model based on a Language Model called BERT with the goal
of taking any text input, and generates a numeric vector
in its vocabulary space (30522 dimensional), with each entry representing a relevance score of the
corresponding word for the given text.
As a concrete example,
consider the query “what is a car”. Using the plain bag-of-words representation, the output would be an
all-zero vector of 30522 dimensions, except a 1 for the
words “what”, “is”, “a”, and “car”. The problem with this naive approach is that, all documents that do not
contain any of these 4 words will never be retrieved,
even though they could be relevant (e.g. it uses the word “vehicle”).
SPLADE is essentially a more
advanced version of this process, but has the ability to
assign non-zero scores to words that are not in the original text. In this example, SPLADE would generate an
output that assigns the word “car” a score of 2.84,
“cars” 2.19, “vehicle” 1.25, etc. Even words such as “science” and “technology” received non-zero scores.
SPLADE uses an inverted index for fast retrieval, as a result, the end to end process
involves two stages: offline indexing, and online retrieval.
For offline indexing, we take all the
candidate passages, and run each of them through the SPLADE algorithm. This essentially generates a sparse
representation of what could be conceptually thought of as a very large `m` by `n` matrix, where `m` is the
number of passages, and `n` is the number of words in the BERT vocabulary, in this case, 30522, and each entry
is the score of the word for the corresponding passage.
Even though this is conceptually a very large
matrix, for fast retrieval, in practice, it is persisted on disk in a columnar, sparse fashion. More specific
ally, the data consists of a number of keys, with each key being a word in the vocabulary space. Inside each
key, 2 arrays respectively representing which passages contain this word, and what their corresponding scores
are, are stored.
For the online retrieval process, when a query comes in, it also goes through the SPLADE
algorithm to obtain the words and weightings. Then we iterate through the words that are relevant to the query
and accumulate the scores for each passage. This process is mathematically equivalent to multiplying the
overall index matrix by the SPLADE representation of the query.
Once we obtain the scores of each passage
relative to the given query, we do a partial rank, and provide the top results. These are exactly the top
results returned for this query, completing the information retrieval process.
There are a few dimensions along which an information retrieval algorithm is typically
evaluated on.
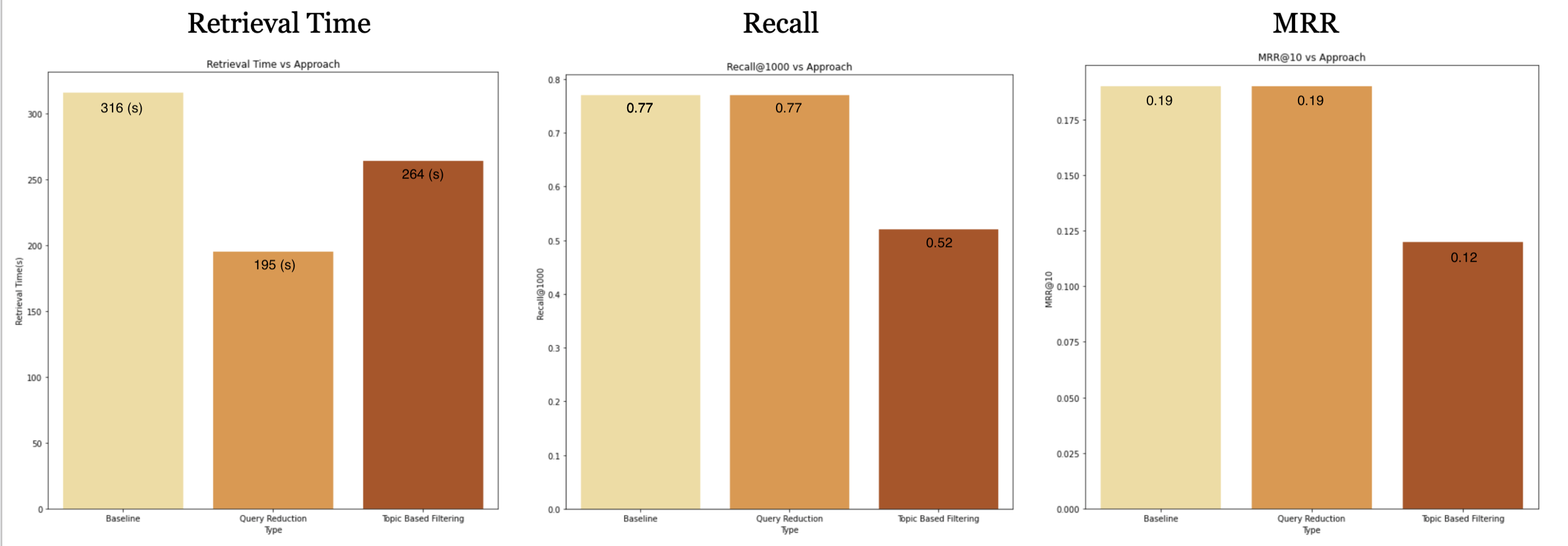
• Mean Reciprocal Rank: This represents how high up, on average, the ground truth
relevant results are ranked by the algorithm.
• Recall@1000: This represents the percentage of times the relevant passages (out of
many more irrelevant ones) are included in the top 1000 results at all
• Retrieval Time: This represents how fast the algorithm is able to generate the
results for a given query
For our project, our goal is to improve Retrieval Time of the SPLADE algorithm with minimum sacrifice
on the other accuracy metrics.
In the original SPLADE information retrieval (IR) system, the SPLADE generated query and document embedding similarity scores are exhaustively calculated. That is for Q queries and D documents, we generate QxD similarities. Our approaches center around improving the search component of the IR system by reducing the number of Query-Document similarity calculations computed at inference time.
The high level idea here is to apply a faster filter to passages during document retrieval based on its topic, before it gets ranked along with all the passages. This insight comes from the observation that typically a query only falls within the realm of a small number of topics (e.g. sports, or history), and as a result, there are a large number of passages that can be filtered out purely based on its topic and does not need to enter the ranking stage of retrieval, since even if their score is 0, it still contributes to the time complexity of the ranking algorithm. As a result, our hypothesis is that it will make retrieval faster, especially when there are a large number of passages to retrieve from.
To vastly improve search time we employed a number of clustering methods. By first comparing an incoming query with a representation of a cluster of passages, we will be able to reduce the number of passages evaluated for similarity to the query. Our tree-based approaches followed a similar pattern to that of the topic filtering. In all cases, we first train a clustering model on the passages offline. At retrieval time we infer the cluster of the incoming query and use the stored passage cluster assignment to gather a specified number of similar passages based on that query cluster assignment. Next we go through the normal retrieval process using the inverted index adding an additional filtering step based on passage inclusion in the retrieved passage set from the cluster model. Only the coincident subset of passages from both the clustering model and the inverted index are then used in calculating the similarity scores.
This is our simplest approach to improving retrieval efficiency. This invovles reducing the size of the query.
For our experiments, we use the MS MARCO open dataset, specifically its full validation set
to evaluate our algorithms performances.
MS MARCO is an open dataset from Microsoft that was generated from real life Bing searches. Its full
validation set consists of 1600 queries, and 276,142 passages to retrieve from. For each query, 1-3 passages
have been manually determined as relevant, which is used as the ground truth for calculating the accuracy
metrics such as MRR and Recall.
Our algorithm is based on a pre-trained flavor of SPLADE available on Huggingface as
naver/splade-cocondenser-ensembledistil. We did not retrain the SPLADE model in any way, and only tuned its
indexing and retrieval processes.
For the topic based approach, we used a pre-trained classifier (hf: cardiffnlp/tweet-topic-21-multi) to
classify the topic of all the passages and queries.
The topic classification of passages are pre-computed offline using a large notebook instance
(ml.c5d.9xlarge), while the retrieval experiments were all carried out in a ml.c5d.2xlarge instance.
The goal of our project was to reduce the retrieval time of neural information retrieval and we successfully did that while also maintaining MRR@10 and Recall@1000! The best performing approach was the Query Reduction Approach and we were able to reduce it by 121 sec or 2 min.