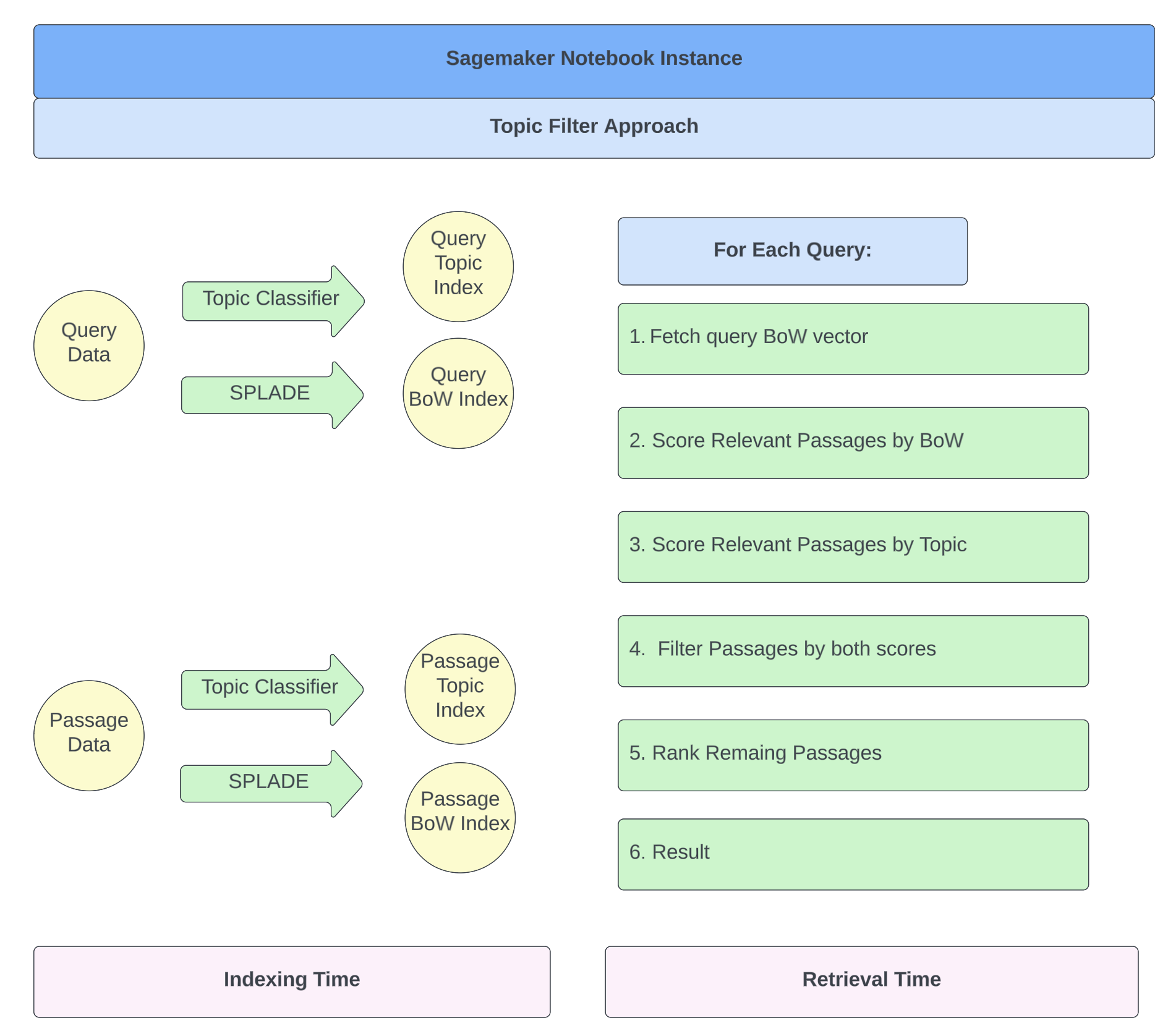
Topic-Based Approach
The high level idea here is to apply a faster filter to passages during document retrieval based
on its topic, before it gets ranked along with all the passages.
Concretely, our retrieval algorithm is as follows:
- In addition to having a sparse index in the vocabulary space for each passage, also use a pre-trained topic model to generate a sparse index which contains a topic score for each passage over the fixed topics (there are 19 of them).
- Given an incoming query, use the same model to score this query against the same topics
- Trim the topic vector of this query so only scores above a QUERY_THRESHOLD remain, and other topics will be set to 0. This makes the topic vector sparse.
- Alternative to 3, is to trim the topic vector of this query so only top k topics are kept, which results in a similar sparse topic vector
- Load the topic scores of all passages in memory, then trim them as well, so only scores above PASSAGE_THRESHOLD remain, the other entries will be set to 0. This makes the passage topic vectors sparse too.
- Similarly, alternative to 5, we can keep only the top m entries in each passage topic scores too
- As part of the SPLADE process, when scoring the passages for each query, consider if the query has any overlap of topics with the passage. If not, directly eliminate this passage from consideration and exclude this passage from the ranking stage.
- If yes, we could either weigh SPLADE score by the dot product (or cosine similarity) between the topic vectors of the query and the passage, or simply use the SPLADE score directly. The former will give passages that have a strong topic overlap with the query a higher weighting, and serve as another distinguishing factor between passages, however the latter will be significantly faster, since it removes the computation of the doc products.
Experiments and Results
As described in the previous section, there are a number of parameters that lead to different
configurations of the retrieval algorithm. Notably:
• Query Topic Filter Threshold: If less than 1, the topic score of the query is set to 0 if
below the threshold. If greater than 1, this is the number of top topics to remain in the query topic
vector.
• Passage Topic Filter Threshold: If less than 1, the topic score of the passage is set to 0
if below the threshold. If greater than 1, this is the number of top topics to remain in the passage
topic vector.
• Final Score Filter Threshold: When retrieving passages for a given query, the pair’s
relevance score is determined by the dot product of their SPLADE vectors. If the final relevance score
is below the threshold, it’s set to 0 and does not enter the passage ranking.
• Weighed by Topic Overlap: A true/false configuration that determines whether the relevance
scores calculated by SPLADE gets weighted by the topic overlap of the passage and the query too.
With a large number of possible configurations, we’ve taken a manually guided approach and tried a
number of combinations as we aim to optimize for the retrieval time with minimum impact on accuracy.
Below is the full set of results of all experiments we conducted, ranked by accuracy (MRR and
Recall@1000) in descending order.
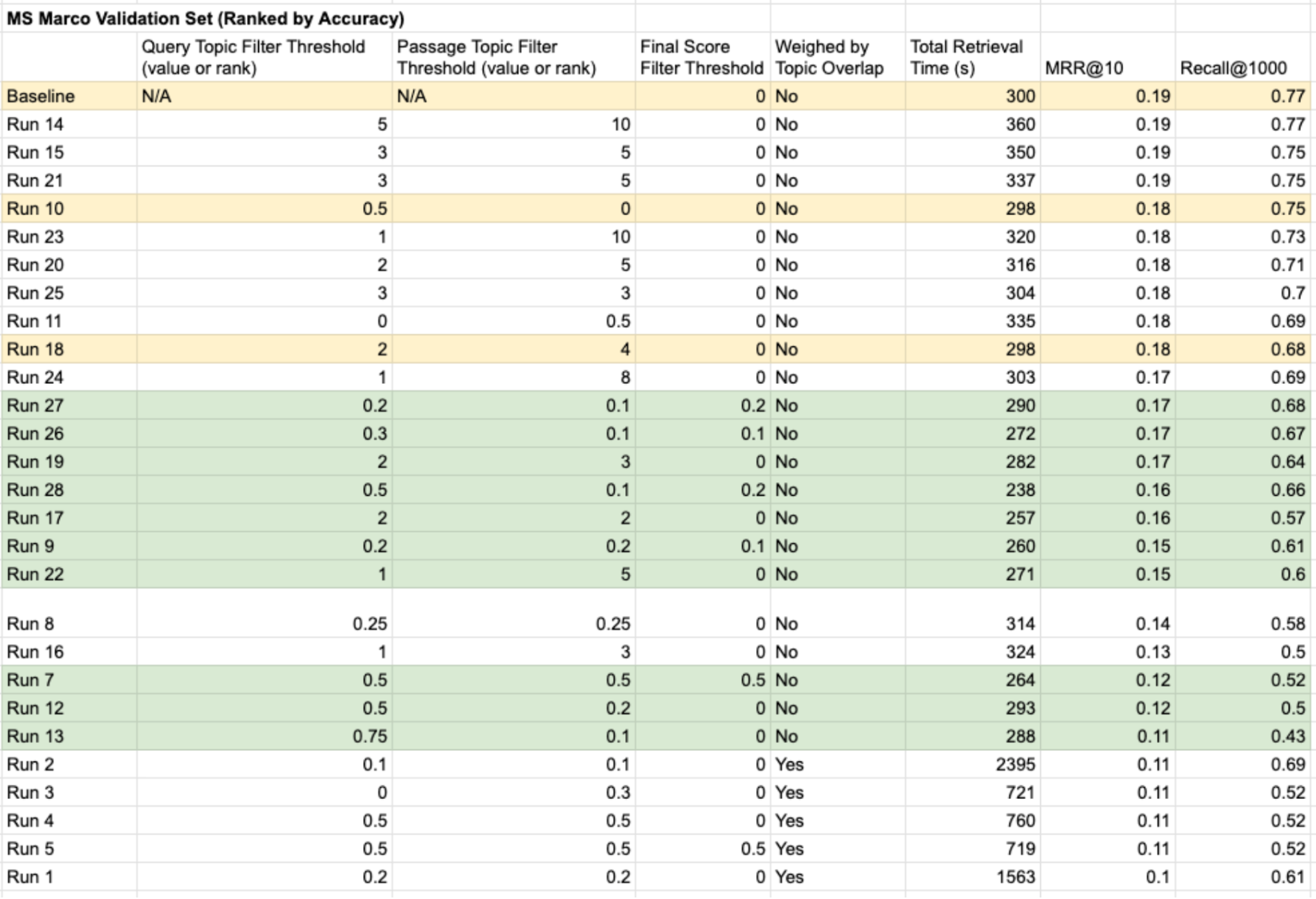
As can be seen, the baseline SPLADE model still has the highest accuracy metrics. However, there is
a spectrum of different configurations that can achieve different trade-offs between retrieval time
and accuracy, for example Run 19, where only top 2 topics of each query and top 3 topics of passage
are kept and used to filter the passages, can accelerate retrieval time by about 6%, with a only a
slight loss of MRR from 0.19 to 0.17.
Overall, there are some positive results and learnings from this approach, for example:
• We’re able to speed up retrieval time by as much as 20% (Run 28) with still fair
acceptable accuracy
• Weighing SPLADE scores by topic overlap incurs a lot more computation for no gain on
accuracy
• Keeping a broader number of topics on the passages are more important than on the
queries, since the passages are longer and could be relevant to a broader set of topics
•Of course, the pre-trained topic classifier makes a major difference in the timing and
accuracy of the overall algorithm, however we were not able to explore its concrete effects.